How Instagram computes real-time trending hashtags ?
System behind Instagram trending.

I am sure, you might have used Instagram and explored it's trending section. Instagram has built a brilliant system in-house, to parse ~85M new photos and 700M hashtags everyday from over 500M users to compute realtime trending content.
In this article, we will deep dive into how Instagram approached identifying, ranking and presenting the best trending hashtags realtime in the Instagram app.
What is a trending hashtag actually?
In simple words, a hashtag is trending whenever there is an unusual number of people who are sharing posts using that hashtag, as a result of something happening in that moment.
So, they identified three main elements to a good trending hashtag -
Popularity : The trending hashtag should be of interest to many people.
Novelty : It should be about something new. Means, people were not posting about it with the same intensity.
Timeliness : It should surface while respective event is taking place.
How to identify a trending hashtag?
If the observed activity (no of media shared using that hashtag) for any hashtag is higher than it's expected activity, then we can say, this is something that is trending and we can determine their trending ranks based on their differences from the expected values.
Example -
Let's say every hour Instagram observes that there are only a few posts shared using a hashtag for example #hashnode but one day the community realises @hashnode potential and it became famous. Thousands of people started sharing content using the hashtag. This means that the activity now is higher than what was expected and hence we say that It's trending
In reverse, more then 100K posts are shared with #love everyday as it is a very common and popular hashtag. Even if, 10K extra posts (total 110K) are observed any day, it won't be enough to be counted as trending.
How Instagram implemented it?
Initially, for each hashtag, Instagram stored the counters of posts shared using hashtag, in each 5 min window for the last 7 days.
Counter for hashtag h for time (t-5 -> t) window = C(h,t)
After normalisation, probability of hashtag h at time t = P(h,t)
Based on this data, they built an AI model which will predict expected number of counters C'(h,t) and probability P'(h,t) at time t.
So, KL divergence score (It's a measure of how much one probability distribution differs from another probability distribution) =
P(h,t) * ln (P(h,t) / P'(h,t))
Here,
P(h,t) -> Popularity
P(h,t) / P'(h,t) -> Novelty
t -> Timeliness
And based on t, they were able to show real-time trending hashtags.
Accurate prediction Problem
It was not as simple as it looks. There were so many challenges Instagram faced while it's implementation -
- Storing counters for all hashtags for every 5 min window was high memory demanding
- High possibility of random hashtag usage spikes as Instagram was looking at 5 min window data
- Majority of the hashtags got ~0 new posts so they were not able to compute KL divergence score (due to divide by zero)
So, they modified the algorithm a bit to compute baseline probability given past observations.
The more accurate you want to be, the more time-and-space complexity the algorithm requires.
After experimenting with a few alternatives, they figured out that every 5 min window hashtag count was not a good idea due to various reasons. So, to calculate baseline probability, they started looking at a few hours worth of data (last few hours data and same hour data of previous weeks etc) to avoid high memory demand and random hashtag usage spikes.
But still, predicted baseline probability was still zero for few hashtags and computation of KL divergence was not possible. To overcome this issue, it was observed that majority of the hashtags do not get more then three posts per hour. So, for those hashtags they simply marked it as if they saw 3 posts in that time-frame and dropped counters for all those hashtags. It cut down >90% memory usage.
It came with the cost. As the longer the time frame is, the more data they have, but the slower it will be to identify a trend.
Ranking Trending hashtags
Next challenge was to rank all hashtags based on their trendiness.
Instagram Approach -
- Aggregate hashtags for a given country/language
- Sort them based on KL divergence score
- Impose lower bound to get rid of non-interesting trending hashtags
- Return list of interesting trending hashtags
BUT they encountered one interesting issue here. Suppose, #hashnodeHappyHours event is going on and people are talking a lot about it. As soon as event is over, amount of new posts using this hashtags will decrease. Therefore, it's KL score will also quickly decrease and the hashtag won't be trending anymore BUT people usually like to see posts from an event for a few hours after it is over.
To overcome it, exponential decay function was used to define TTL for previous trends.
Exponential Decay value
Sd(h, t) = SM(h) * (1/2)^((t — tmax)/half-life)
SM(h) is maximum KL score for a hashtag. tmax is the time when KL score was maximum
After setting half-life to be two hours (SM(h) is halved every two hour), hashtag will still showup in trending.
Grouping similar trending hashtags
Once we have real time trending hashtags, it's very important to group similar trending hashtags and only show the best representative of the group because people use a range of different hashtags to describe the same event and showing multiple hashtags related to same event can lead to annoying user experience.
To calculate similarity matrix for each pair of trending hashtags, hashtag grouping system rely on Co-occurrences, Edit distance (using Levenshtein distance algorithm which efficiently calculates the minimum number of single-character edits between two words) & Topic distribution (using Term frequency-inverse document frequency).
Backend System
Trending backend system is designed as stream processing application with four nodes.
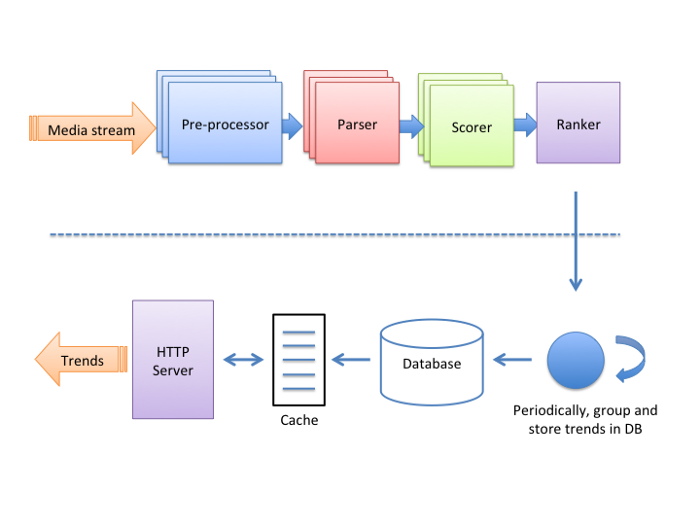
Pre-Processor - It talks to Media service and fetch metadata of post and prepares all the data for the next step.
Parser - It extracts hashtags used in the content and streams it in the output. Along with it, it goes through a set of quality filter rule which removes bad hashtags.
Scorer - It stores time-aggregated counters for each quality hashtag in memory and computes trendiness score.
Ranker - It collects all the hashtags along with their trending scores and ranks them based on certain rules.
It collects all the hashtags along with their trending scores and ranks them based on certain rules.
Important thing to note here is, the whole architecture is stream lined as each one of them is taking care of a different partition therefore as many parallel instances can be run without compromising the whole trending system in case of system failure.
Source - Instagram Engineering Blogs.
Thanks for reading. I would love to hear any corrections or additions!




